
Think of Google as a massive library. Crawling is like the librarian walking through the shelves, scanning new books. Indexing is when they actually put those books into the catalog, making them searchable for readers. Without the catalog entry, your book just gathers dust in the back.
Let’s break this down step by step in plain English.
Why Crawling and Indexing Matter for Your Website
Imagine you just launched a new blog about cooking. You post ten delicious recipes with beautiful photos. But when you search Google for your own site, nothing shows up. Frustrating, right? That’s because Google hasn’t crawled or indexed your site yet.
Without crawling, search engines don’t even know your pages exist. Without indexing, even if they find your pages, they’re not stored in the system, which means no chance of ranking. No crawling + no indexing = no traffic. Simple as that.

So, if you care about being visible on the internet, you need to understand this process.
What is Google Crawling?
In simple words, crawling is Google’s way of discovering content on the web. Google uses little programs called Googlebots (or spiders) that move from one link to another, scanning your website pages.
How it works:
The bot lands on your homepage.
It follows your internal links (like “About,” “Contact,” or “Blog”).
It scans the content, loads the code, and checks for other linked pages.
Then it keeps hopping to new links like a curious kid exploring a new town.
If crawling was a person, it would be the friend who just can’t stop clicking on “Next Video” on YouTube.
Crawlability
“Crawlability” means how easy it is for these bots to access your site. If your site is well-linked, loads fast, and doesn’t block bots in the robots.txt file, it’s crawlable. If not, Google may skip it.
You can check crawl status using Google Search Console. There’s also the classic Google crawler test where you fetch and render your pages to see what bots can access.
What is Google Indexing?
Once crawling is done, Google decides whether your page is worth storing in its giant database, this is indexing.
Think of it like this:
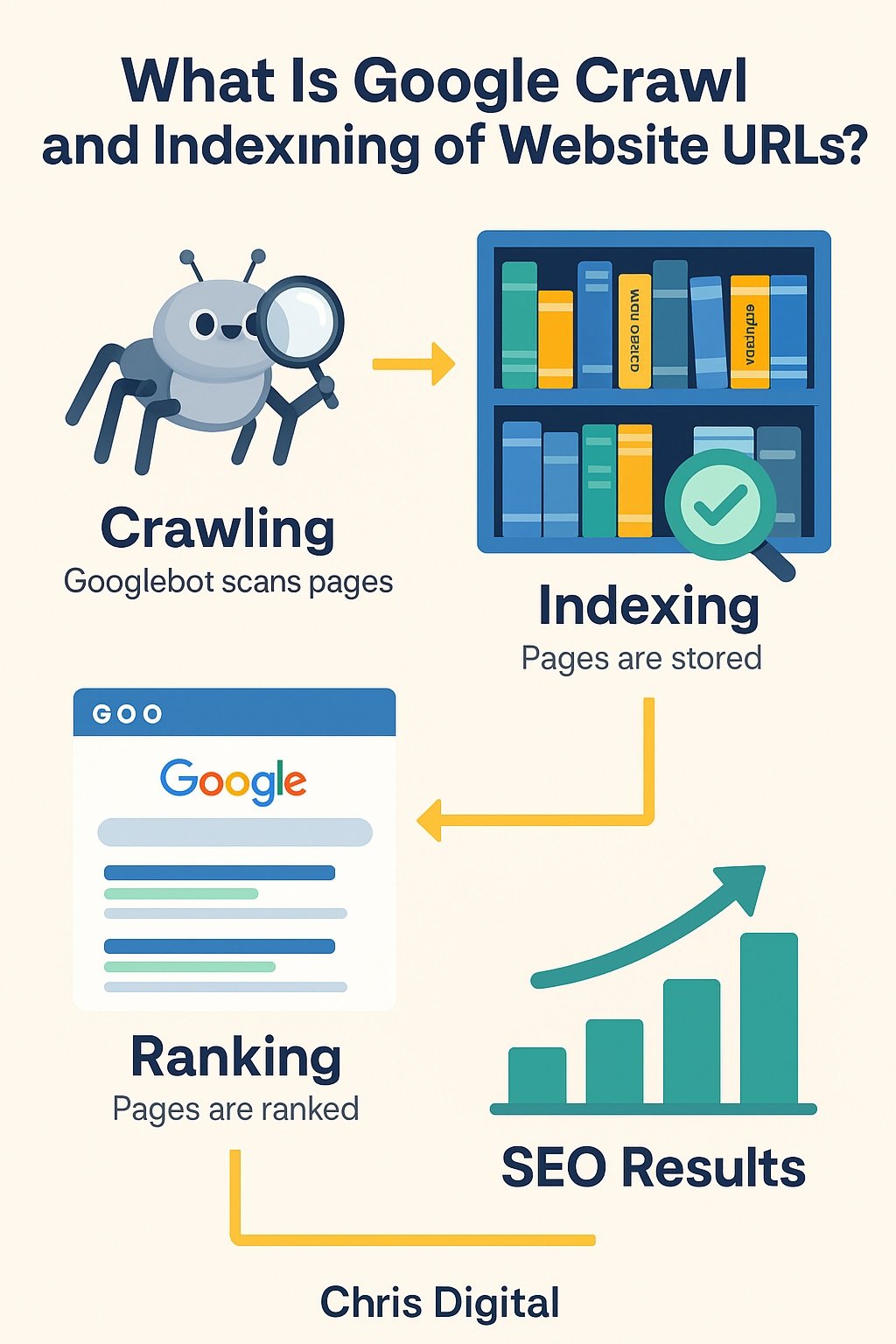
Crawling = Google finds your page.
Indexing = Google saves it in the library.
Ranking = Google decides where to show it when someone searches.
When your page gets indexed, it’s now eligible to appear in Google search results. Without indexing, it doesn’t matter how good your content is, it won’t show up.
To check if a page is indexed, type this in Google:
If it appears, congrats, it’s in the index. If not, you need to fix something. Tools like a Google index checker can also help.
Crawling vs Indexing vs Ranking (Quick Comparison)
Here’s a simple way to see the difference:
| Step | What it Means | Example |
|---|---|---|
| Crawling | Google discovers your page | Librarian finds a new book |
| Indexing | Google stores your page | Book added to the library catalog |
| Ranking | Google shows your page in search | Book recommended to readers |
See the flow? First you get found, then stored, then shown.
How Google Crawls Your Website
Now let’s talk about the nuts and bolts.
Google usually starts with:
Sitemaps – Your XML sitemap tells Google what pages exist.
Internal links – Pages you link to from your site.
Backlinks – Other websites pointing to you.
Google also uses a crawl budget. That means it decides how many pages it’ll crawl on your site during a given time. If you’ve got a huge website, not all pages may get crawled every day.
Things that hurt crawling:
Broken links (404 errors).
Slow site speed.
Blocking bots in robots.txt.
Orphan pages (pages with no internal links pointing to them).
How Google Indexes Your Website
After crawling, Google looks at a few signals before indexing:
Content quality: Thin, duplicate, or spammy content often doesn’t get indexed.
Mobile-first: Google checks how your page looks on mobile before deciding.
Canonical tags: If you have duplicates, the canonical tag tells Google which version to index.
Sometimes, you’ll see issues like “Discovered – currently not indexed” in Search Console. That means Google knows the page exists but decided not to store it yet, often because of low value or limited crawl budget.
Tips to Improve Crawlability and Indexing
Here’s the fun part, what you can actually do:
Submit a sitemap in Google Search Console.
Link pages internally so bots can move around easily.
Fix broken links and redirects.
Keep content fresh and valuable.
Avoid duplicate content by using proper canonical tags.
Optimise site speed, Google loves fast-loading sites.
Use structured data (Schema) to help Google understand your content.
Remember: Google rewards useful, unique, and fast websites.
Common Problems with Crawling & Indexing
Let’s be real, almost every blogger faces these at some point:
Pages not appearing in Google – Usually blocked or not indexed.
“Discovered but not indexed” – Means Google isn’t convinced your page is worth storing yet.
Thin content – Short, low-value pages rarely get indexed.
Duplicate content – If you copy from elsewhere, Google might skip indexing.
The fix? Audit your site regularly. Use Search Console reports. Rewrite low-value pages with more detail (a Paraphrasing Tool can help refresh content smartly).
Practical Tools You Can Use
Google Search Console – The must-have tool. Shows crawl stats, indexing issues, and sitemap status.
Google Index Checker – Quick checks for individual pages.
Screaming Frog SEO Spider – Lets you see your site the way Googlebot does.
Ahrefs / SEMrush – Pro SEO tools that track indexing and crawling issues.
Final Thoughts
Here’s the bottom line:
Crawling is how Google finds your pages.
Indexing is how Google stores them.
Ranking is how Google shows them to searchers.
If your site isn’t indexed, you’re invisible. If it’s indexed but not ranking, you need to work on SEO. Both crawling and indexing are the foundation, without them, nothing else matters.
So don’t just publish and pray. Take control. Submit your sitemap, fix crawl issues, improve content, and check regularly in Search Console. Do that, and you’ll move from “invisible” to “unmissable.”

Chris Digital, tech enthusiast and digital marketer, shares insights on WordPress, SEO, Adsense, online earning, and the latest in graphics and themes.